by Irene Rossi
In the last thirty years, the application of information technologies to the study of both material and immaterial cultural heritage has deeply changed the tools and conditioned the methods of historical, archaeological/artistic and textual/linguistic inquiry. At the crossroads of those three areas of research, epigraphy has much benefited of, and at the same time contributed to the advancements in the digital treatment of primary sources. Around the year 2000, the advantages of the WWW for scientific research and dissemination stimulated the undertaking of projects of electronic cataloguing and online fruition of epigraphic corpora, in the fields of both Classical and Near Eastern studies (see, among others, the Epigraphic Databases Roma–EDR, Bari–EDB, and Heidelberg-EDH; the Corpus Inscriptionum Phoenicarum necnon Poenicarum–CIP; the Cuneiform Digital Library Initiative–CDLI).
The Chair of Semitic Philology at the Dipartimento di Scienze Storiche del Mondo Antico of the University of Pisa, Alessandra Avanzini, launched in 1999 the project of a digital Corpus of South Arabian Inscriptions–CSAI, whose initial bulk was published online in 2001, with the objective of collecting the whole of the epigraphic heritage originating from the ancient Yemen and adjacent areas – the Arabia Felix of the classical authors – during the 1st millennium BC until the advent of Islam. The system for the digitization of inscriptional texts and metadata, developed by the “Centro di Ricerche Informatiche per i Beni Culturali” (CRIBeCu) of the Scuola Normale Superiore of Pisa, was based on the adoption of the SGML and later XML metalanguages, providing enough standardization and flexibility at the same time, with a specific DTD for the definition of the mark-up adopted. Combined queries on the epigraphic text, the textual encoding and the metadata were performed by means of the search engine TReSy (acronym for Text Retrieval System).
In the following years, related projects such as MENCAWAR and CASIS contributed to the content and technical implementation of the CSAI archive, ultimately leading to the conception and funding of a wider project, DASI – Digital Archive for the study of pre-Islamic Arabian inscriptions (ERC Advanced Grant, 2011-2016). The general objective of DASI was to enhance the knowledge of the whole of Ancient Arabia through the study of its extremely rich epigraphic corpus, composed of hundreds of thousands of inscriptions in Semitic languages written in different alphabetic scripts – mainly Ancient South Arabian, Ancient North Arabian and Aramaic. These are the only textual primary sources for the reconstruction of the history, the languages and – in general – the culture of this part of the ancient Near East, whose tradition of studies had been rather marginal even among Semitists. DASI archive, which is currently implemented by the Dipartimento di Civiltà e Forme del Sapere of the University of Pisa together with the Istituto di Studi sul Mediterraneo Antico of the CNR, contains nearly 10,000 inscriptions, of which 8,500 are published online. The majority of DASI texts are in the Ancient South Arabian languages, due to the CSAI inheritance, but a number of inscriptions in the Nabataean and Ancient North Arabian languages have enriched the archive, thanks to a partnership with the CNRS-UMR 8167 and with the project OCIANA of the University of Oxford.
The new archival system, created at the Scuola Normale Superiore of Pisa, is made of a MySQL online relational database capable of managing a distributed workflow, with a data entry interface designed to ease the users’ work. The entities composing the conceptual model of the relational database are: Epigraph, Translation, Object, Site, Bibliography, Image, Editor, Corpus, and Collection. The core of the conceptual model, that is the Epigraph entity, contains the metadata of the text (linguistic features, writing, chronology, type of text, notes of apparatus criticus, general and cultural notes) plus a module for the textual transcription (Latin transliteration, UTF-8 set) and XML encoding of various phenomena (e.g. transcription phenomena, editorial interventions, onomastics, grammar). The hybrid DB/XML system was developed in order to benefit from both the advantages of an online database – easy cataloguing, update data shared among users, secure access, controlled management of the workflow– and the flexibility in textual encoding granted by the XML language, whose TEI-EpiDoc standard was adopted. This mixed approach proved extremely suited to the peculiar dual nature of the epigraphic source, which is physical and textual at the same time, allowing specialists in different disciplines to consistently contribute to the study of a complex documentation made of textual, archaeological, geographic, artistic, visual, bibliographic data.
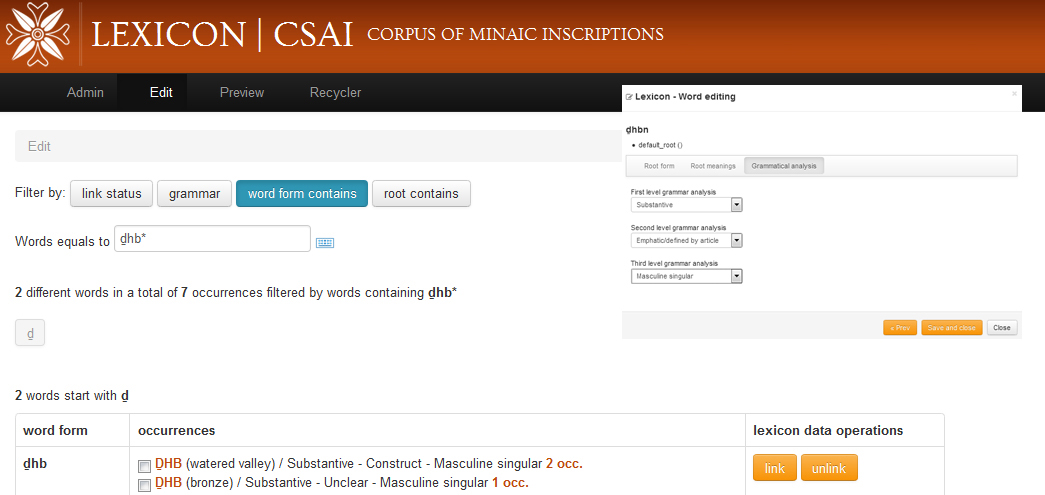
Lists of controlled terms – like those for textual categories, object typologies, iconographic elements – have been at the centre of an essential process of definition of cultural concepts, in a domain of study which still lacks fixed repertoires. The archive is therefore a tool and a place of research in progress itself. In view of the highest level of interoperability, attempts at an alignment of terms to the thesauri defined for other cultural domains have been made (e.g. the Getty AAT and the EAGLE vocabularies), highlighting the potentialities and at the same time the limits of this harmonization procedure, which should first and foremost point out and valorise cultural specificities. An OAI-PMH repository of epigraphic files mapped to several standards (DC, EDM, EpiDoc) grants that DASI data are harvestable and reusable. The editions of the epigraphs with their contextual information, published in the front end site of the archive, can be browsed and searched at different levels of granularity. The research on the texts has always been one major interest of the project, as the history of studies of the languages of pre-Islamic Arabia, fragmentarily attested only through inscriptions, is very recent. The textual search tool allows searches for words or word patterns within a phrase, combining different lexical, onomastic and extra-textual parameters. A separate but connected tool, DASILexicon, has also been developed for the lexicographic study of under-resource epigraphic languages.
The collection, systematization and publication of several digital epigraphic corpora on the web not only has made a tremendous amount of curated editions of inscriptions easily consultable, but it has also stimulated a renovation in the research questions of Digital Epigraphy as a discipline and opened new perspectives of interconnections with other domains. Moreover, it has greatly contributed to the digital preservation of cultural heritage at risk. The cooperation of DASI with the Yemeni General Organization of Antiquities and Museums, for instance, has allowed to digitally save a documentation of hundreds of pieces which have later been pilled, damaged or destroyed during the ongoing war (e.g. the collection of the Regional Museum of Dhamār).
VMAC – 2017